Benchmark


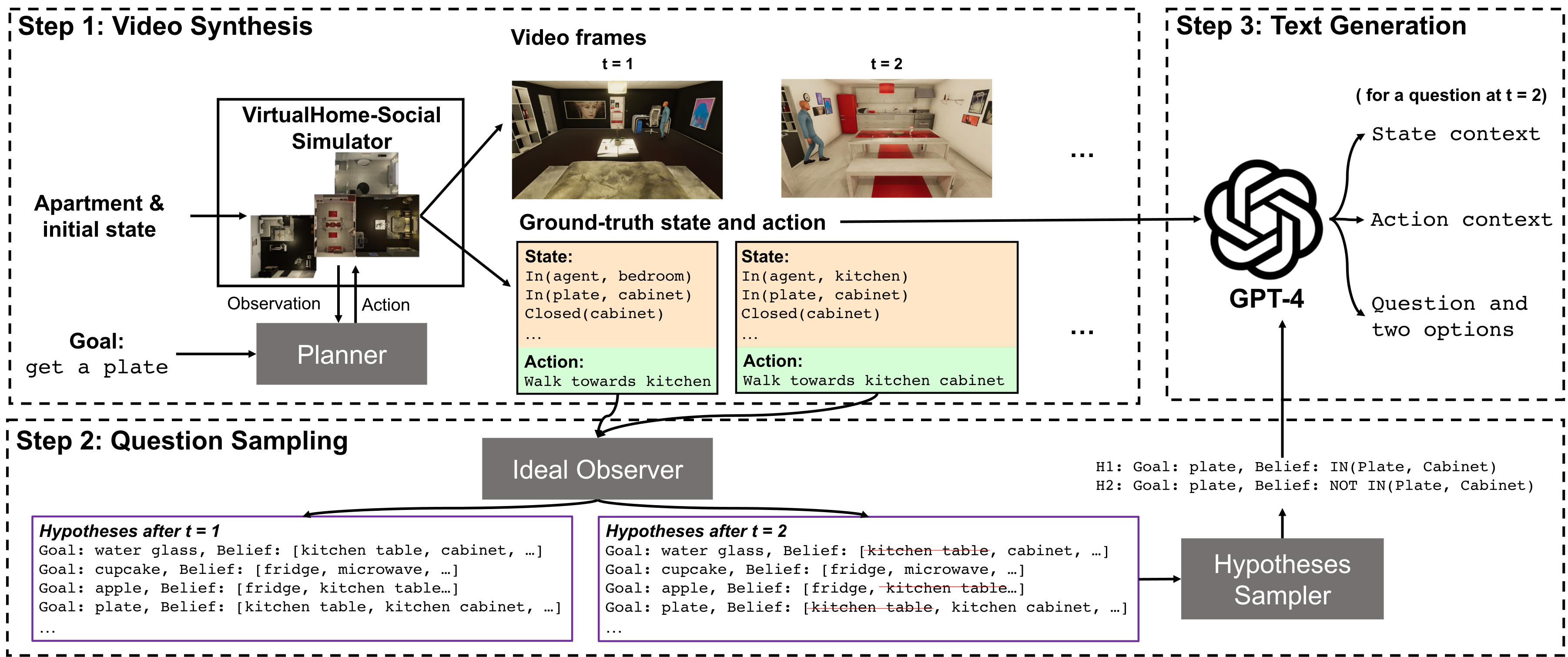
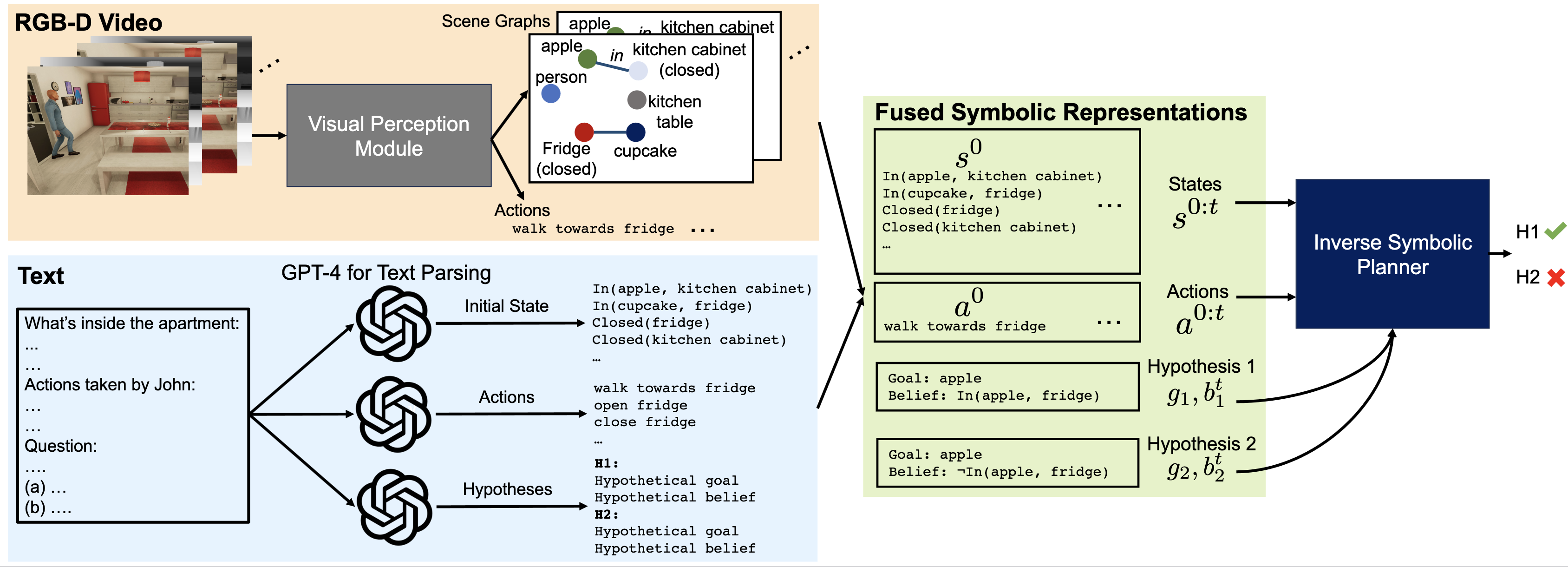
The MMToM-QA Benchmark
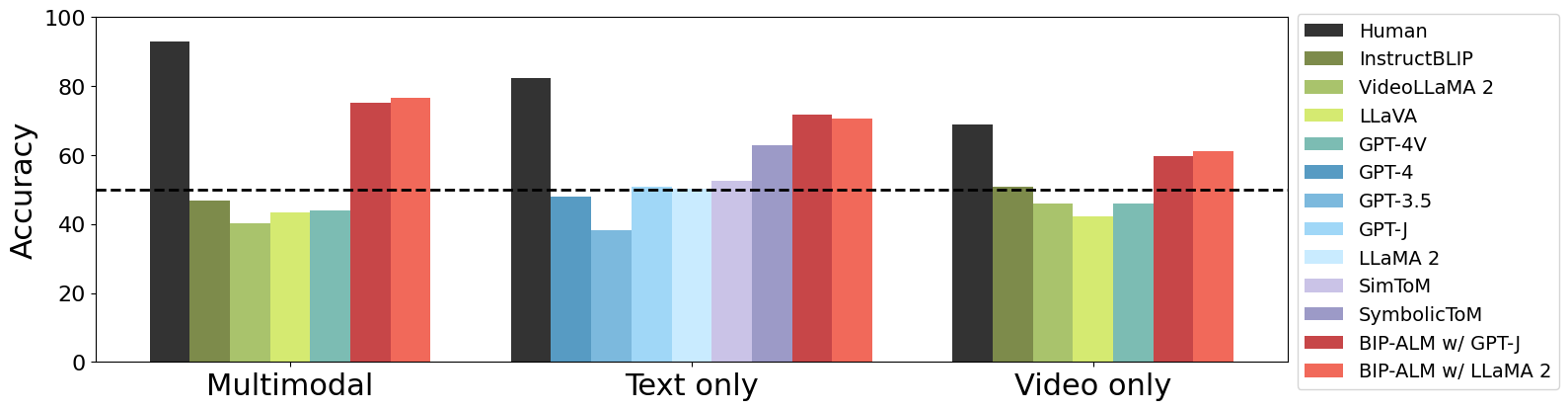
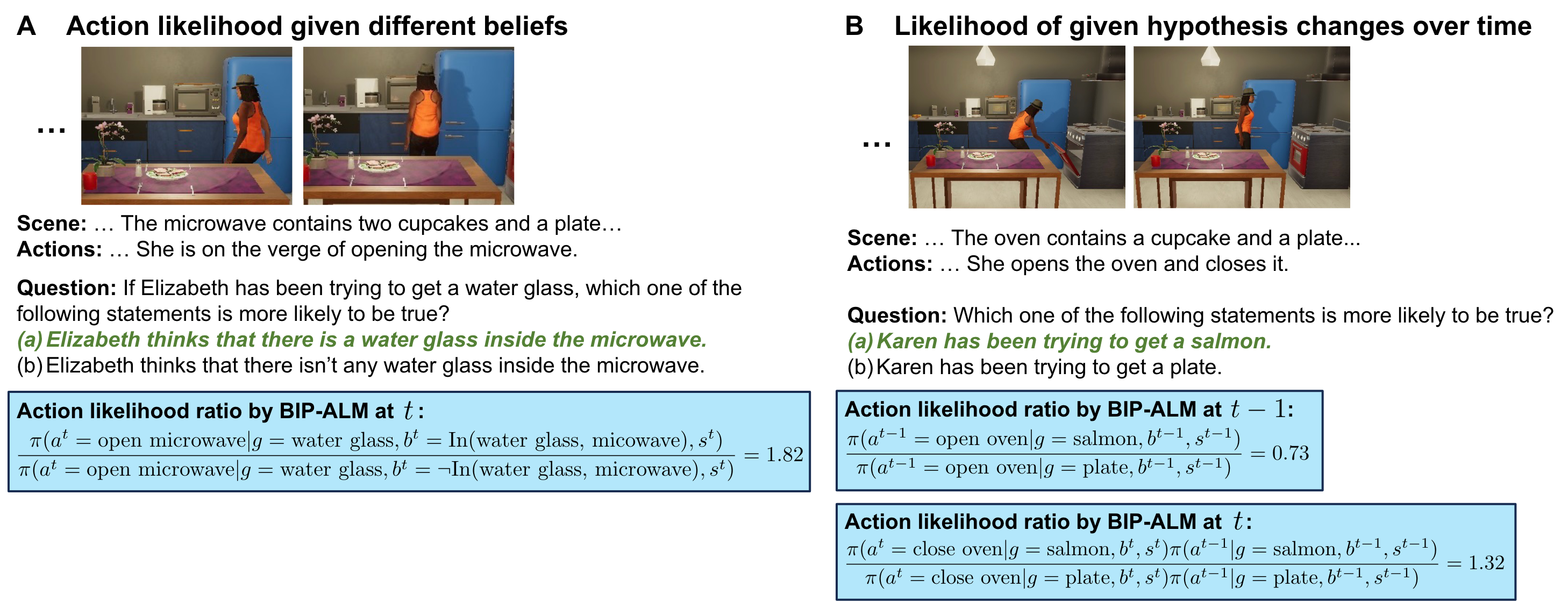
MMToM-QA systematically evaluates the cognitive ability to understand people's minds both on multimodal data and different unimodal data. It consists of 600 questions spanning seven categories that evaluate belief inference and goal inference in rich and diverse household scenarios. Each belief type has 100 questions (300 total); each goal type has 75 questions (300 total).
The benchmark and usage instructions are in the GitHub repository. A text-only version is available on Hugging Face.
Question types in MMToM-QA with examples.
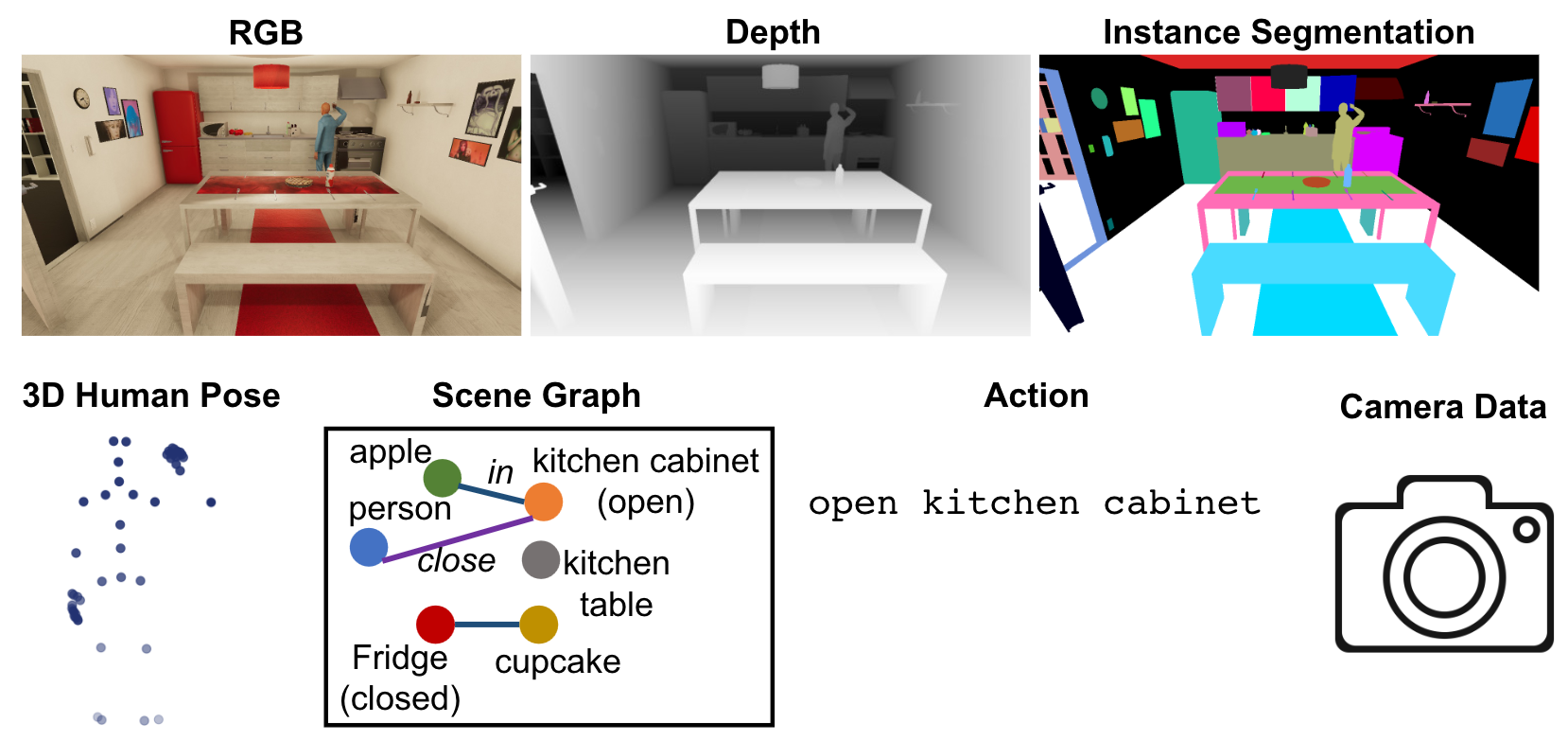
Each question is paired with a clip of the full activity as RGB-D frames, plus a text description of the scene and the actions taken by the person in that clip.
(a) Types of data provided
(b) The procedural generation process